
The secret Of Deepseek
페이지 정보

본문
In a current publish on the social community X by Maziyar Panahi, Principal AI/ML/Data Engineer at CNRS, the mannequin was praised as "the world’s greatest open-source LLM" in accordance with the DeepSeek team’s revealed benchmarks. Mistral 7B is a 7.3B parameter open-supply(apache2 license) language model that outperforms much larger fashions like Llama 2 13B and matches many benchmarks of Llama 1 34B. Its key innovations embrace Grouped-question attention and Sliding Window Attention for environment friendly processing of long sequences. We enhanced SGLang v0.Three to completely assist the 8K context length by leveraging the optimized window attention kernel from FlashInfer kernels (which skips computation instead of masking) and refining our KV cache manager. 특히, DeepSeek만의 독자적인 MoE 아키텍처, 그리고 어텐션 메커니즘의 변형 MLA (Multi-Head Latent Attention)를 고안해서 LLM을 더 다양하게, 비용 효율적인 구조로 만들어서 좋은 성능을 보여주도록 만든 점이 아주 흥미로웠습니다. 이렇게 한 번 고르게 높은 성능을 보이는 모델로 기반을 만들어놓은 후, 아주 빠르게 새로운 모델, 개선된 버전을 내놓기 시작했습니다. 이렇게 하는 과정에서, 모든 시점의 은닉 상태들과 그것들의 계산값을 ‘KV 캐시 (Key-Value Cache)’라는 이름으로 저장하게 되는데, 이게 아주 메모리가 많이 필요하고 느린 작업이예요. DeepSeekMoE는 각 전문가를 더 작고, 더 집중된 기능을 하는 부분들로 세분화합니다.
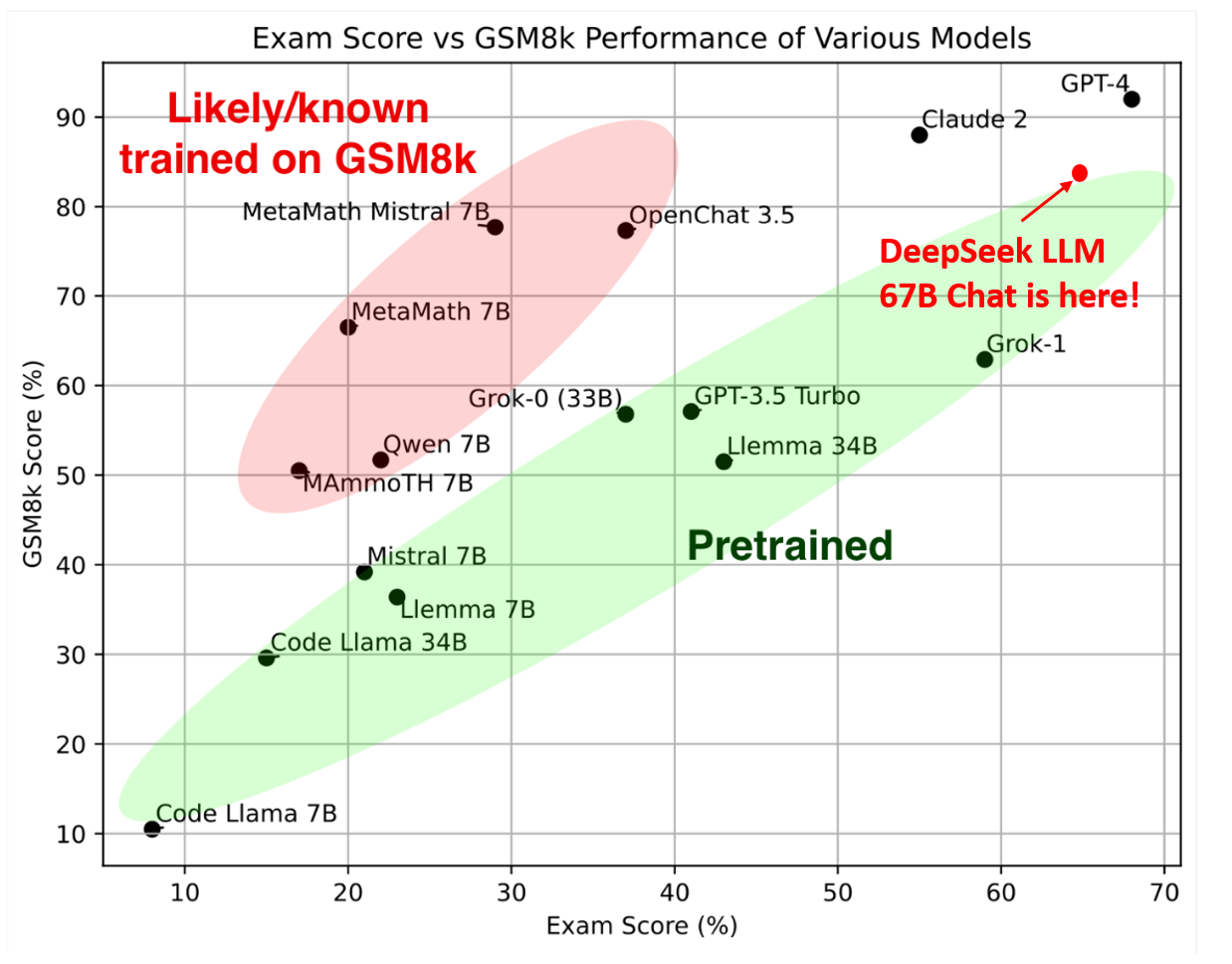 조금만 더 이야기해 보면, 어텐션의 기본 아이디어가 ‘디코더가 출력 단어를 예측하는 각 시점마다 인코더에서의 전체 입력을 다시 한 번 참고하는 건데, 이 때 모든 입력 단어를 동일한 비중으로 고려하지 않고 해당 시점에서 예측해야 할 단어와 관련있는 입력 단어 부분에 더 집중하겠다’는 겁니다. 다른 오픈소스 모델은 압도하는 품질 대비 비용 경쟁력이라고 봐야 할 거 같고, 빅테크와 거대 스타트업들에 밀리지 않습니다. 다시 DeepSeek 이야기로 돌아와서, DeepSeek 모델은 그 성능도 우수하지만 ‘가격도 상당히 저렴’한 편인, 꼭 한 번 살펴봐야 할 모델 중의 하나인데요. DeepSeek 모델 패밀리의 면면을 한 번 살펴볼까요? Particularly noteworthy is the achievement of DeepSeek Chat, which obtained a formidable 73.78% move charge on the HumanEval coding benchmark, surpassing fashions of related measurement. The DeepSeek LLM household consists of 4 fashions: DeepSeek LLM 7B Base, DeepSeek LLM 67B Base, DeepSeek AI LLM 7B Chat, and DeepSeek 67B Chat. Recently, Alibaba, the chinese tech big additionally unveiled its own LLM known as Qwen-72B, which has been skilled on excessive-high quality knowledge consisting of 3T tokens and likewise an expanded context window size of 32K. Not simply that, the corporate also added a smaller language model, Qwen-1.8B, touting it as a gift to the analysis group.
조금만 더 이야기해 보면, 어텐션의 기본 아이디어가 ‘디코더가 출력 단어를 예측하는 각 시점마다 인코더에서의 전체 입력을 다시 한 번 참고하는 건데, 이 때 모든 입력 단어를 동일한 비중으로 고려하지 않고 해당 시점에서 예측해야 할 단어와 관련있는 입력 단어 부분에 더 집중하겠다’는 겁니다. 다른 오픈소스 모델은 압도하는 품질 대비 비용 경쟁력이라고 봐야 할 거 같고, 빅테크와 거대 스타트업들에 밀리지 않습니다. 다시 DeepSeek 이야기로 돌아와서, DeepSeek 모델은 그 성능도 우수하지만 ‘가격도 상당히 저렴’한 편인, 꼭 한 번 살펴봐야 할 모델 중의 하나인데요. DeepSeek 모델 패밀리의 면면을 한 번 살펴볼까요? Particularly noteworthy is the achievement of DeepSeek Chat, which obtained a formidable 73.78% move charge on the HumanEval coding benchmark, surpassing fashions of related measurement. The DeepSeek LLM household consists of 4 fashions: DeepSeek LLM 7B Base, DeepSeek LLM 67B Base, DeepSeek AI LLM 7B Chat, and DeepSeek 67B Chat. Recently, Alibaba, the chinese tech big additionally unveiled its own LLM known as Qwen-72B, which has been skilled on excessive-high quality knowledge consisting of 3T tokens and likewise an expanded context window size of 32K. Not simply that, the corporate also added a smaller language model, Qwen-1.8B, touting it as a gift to the analysis group.
After that, it should get well to full worth. It's going to grow to be hidden in your put up, but will still be seen by way of the remark's permalink. In the example below, I will define two LLMs installed my Ollama server which is deepseek-coder and llama3.1. You need to see the output "Ollama is working". All these settings are one thing I'll keep tweaking to get the best output and I'm also gonna keep testing new models as they turn into out there. Cloud clients will see these default fashions seem when their occasion is updated. It is basically, really strange to see all electronics-including energy connectors-completely submerged in liquid. Users should upgrade to the most recent Cody version of their respective IDE to see the advantages. As companies and builders seek to leverage AI extra efficiently, DeepSeek-AI’s newest release positions itself as a high contender in each common-purpose language duties and specialized coding functionalities. This new release, issued September 6, 2024, combines each common language processing and coding functionalities into one highly effective model.
DeepSeek AI-V2.5 was launched on September 6, 2024, and is obtainable on Hugging Face with each net and API access. I suppose I the 3 totally different firms I worked for where I transformed massive react net apps from Webpack to Vite/Rollup should have all missed that problem in all their CI/CD techniques for 6 years then. The paper's experiments show that merely prepending documentation of the update to open-source code LLMs like DeepSeek and CodeLlama does not allow them to incorporate the adjustments for downside solving. Ask for modifications - Add new features or take a look at cases. The paper presents the CodeUpdateArena benchmark to check how well massive language fashions (LLMs) can replace their data about code APIs that are repeatedly evolving. We recommend self-hosted customers make this alteration when they replace. A free self-hosted copilot eliminates the necessity for costly subscriptions or licensing fees related to hosted solutions. Agree on the distillation and optimization of models so smaller ones become capable enough and we don´t need to lay our a fortune (money and power) on LLMs.
Should you liked this short article along with you would like to receive more info about ديب سيك generously check out the site.
- 이전글The 10 Most Scariest Things About Keyless Car Stolen 25.02.08
- 다음글What Buy A German Driving License Experts Want You To Know? 25.02.08
댓글목록
등록된 댓글이 없습니다.