
The Final Word Technique To Deepseek
페이지 정보

본문
 Ethical Considerations: As the system's code understanding and generation capabilities develop more advanced, it is crucial to handle potential moral considerations, such as the affect on job displacement, code safety, and the accountable use of these applied sciences. These advancements are showcased through a sequence of experiments and benchmarks, which demonstrate the system's strong efficiency in various code-associated tasks. These improvements are significant as a result of they have the potential to push the boundaries of what massive language fashions can do in the case of mathematical reasoning and code-related tasks. Now, here is how you can extract structured data from LLM responses. An intensive alignment process - notably attuned to political dangers - can indeed information chatbots towards producing politically applicable responses. This is one other occasion that suggests English responses are much less likely to set off censorship-pushed solutions. How Far Are We to GPT-4? DeepSeekMath 7B achieves spectacular efficiency on the competitors-degree MATH benchmark, approaching the extent of state-of-the-artwork models like Gemini-Ultra and GPT-4.
Ethical Considerations: As the system's code understanding and generation capabilities develop more advanced, it is crucial to handle potential moral considerations, such as the affect on job displacement, code safety, and the accountable use of these applied sciences. These advancements are showcased through a sequence of experiments and benchmarks, which demonstrate the system's strong efficiency in various code-associated tasks. These improvements are significant as a result of they have the potential to push the boundaries of what massive language fashions can do in the case of mathematical reasoning and code-related tasks. Now, here is how you can extract structured data from LLM responses. An intensive alignment process - notably attuned to political dangers - can indeed information chatbots towards producing politically applicable responses. This is one other occasion that suggests English responses are much less likely to set off censorship-pushed solutions. How Far Are We to GPT-4? DeepSeekMath 7B achieves spectacular efficiency on the competitors-degree MATH benchmark, approaching the extent of state-of-the-artwork models like Gemini-Ultra and GPT-4.
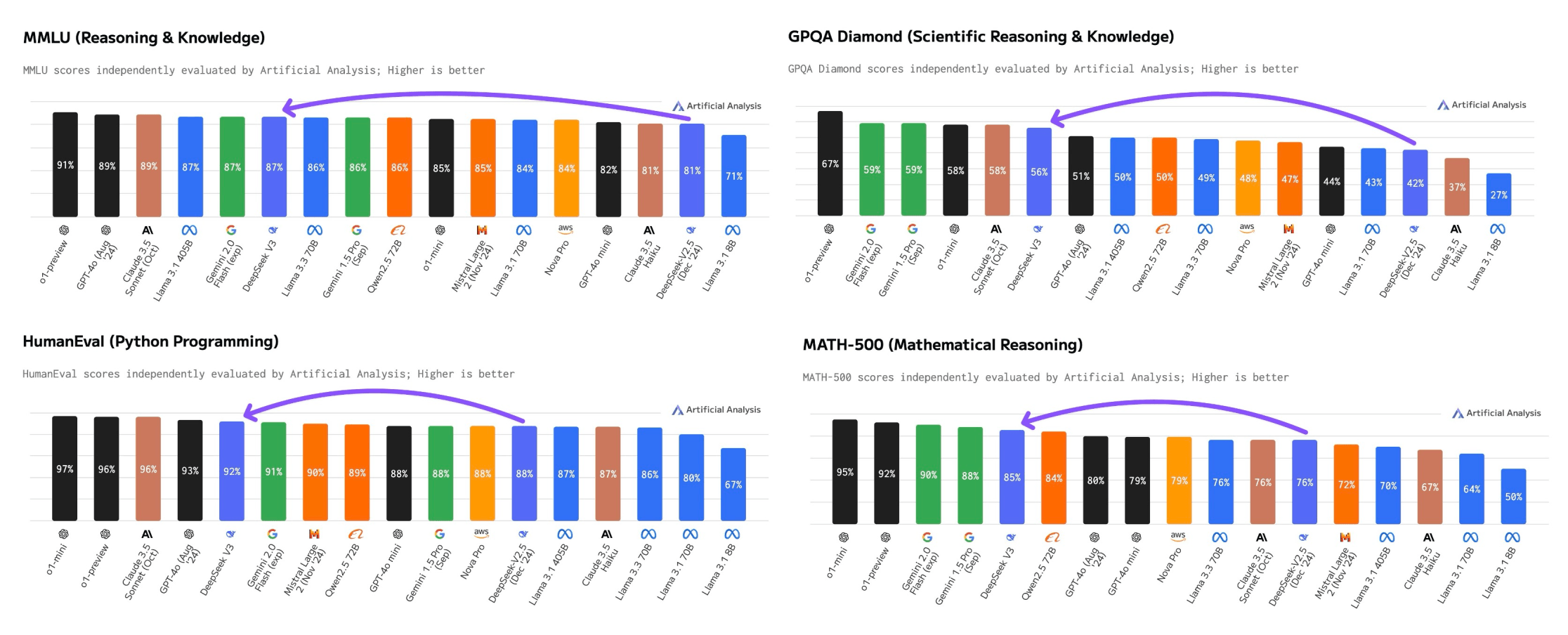 The paper attributes the strong mathematical reasoning capabilities of DeepSeekMath 7B to two key elements: the extensive math-related knowledge used for pre-training and the introduction of the GRPO optimization method. GRPO helps the model develop stronger mathematical reasoning abilities whereas additionally improving its memory utilization, making it more efficient. Despite these potential areas for further exploration, the overall approach and the results presented in the paper signify a significant step ahead in the sector of giant language fashions for mathematical reasoning. As the field of giant language models for mathematical reasoning continues to evolve, the insights and techniques introduced in this paper are prone to inspire additional developments and contribute to the event of even more succesful and versatile mathematical AI techniques. The paper explores the potential of DeepSeek-Coder-V2 to push the boundaries of mathematical reasoning and code era for large language models. The researchers have also explored the potential of DeepSeek-Coder-V2 to push the limits of mathematical reasoning and code era for large language models, as evidenced by the associated papers DeepSeekMath: Pushing the limits of Mathematical Reasoning in Open Language and AutoCoder: Enhancing Code with Large Language Models.
The paper attributes the strong mathematical reasoning capabilities of DeepSeekMath 7B to two key elements: the extensive math-related knowledge used for pre-training and the introduction of the GRPO optimization method. GRPO helps the model develop stronger mathematical reasoning abilities whereas additionally improving its memory utilization, making it more efficient. Despite these potential areas for further exploration, the overall approach and the results presented in the paper signify a significant step ahead in the sector of giant language fashions for mathematical reasoning. As the field of giant language models for mathematical reasoning continues to evolve, the insights and techniques introduced in this paper are prone to inspire additional developments and contribute to the event of even more succesful and versatile mathematical AI techniques. The paper explores the potential of DeepSeek-Coder-V2 to push the boundaries of mathematical reasoning and code era for large language models. The researchers have also explored the potential of DeepSeek-Coder-V2 to push the limits of mathematical reasoning and code era for large language models, as evidenced by the associated papers DeepSeekMath: Pushing the limits of Mathematical Reasoning in Open Language and AutoCoder: Enhancing Code with Large Language Models.
DeepSeekMath: Pushing the boundaries of Mathematical Reasoning in Open Language and AutoCoder: Enhancing Code with Large Language Models are related papers that discover related themes and advancements in the field of code intelligence. It is a Plain English Papers summary of a analysis paper known as DeepSeekMath: Pushing the boundaries of Mathematical Reasoning in Open Language Models. It is a Plain English Papers summary of a analysis paper known as DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence. By breaking down the barriers of closed-supply fashions, DeepSeek-Coder-V2 might lead to extra accessible and powerful tools for builders and researchers working with code. The paper presents a compelling method to improving the mathematical reasoning capabilities of large language models, and the results achieved by DeepSeekMath 7B are spectacular. Since release, we’ve additionally gotten affirmation of the ChatBotArena ranking that places them in the highest 10 and over the likes of recent Gemini professional models, Grok 2, o1-mini, and so forth. With solely 37B lively parameters, that is extremely interesting for many enterprise purposes. This enables for interrupted downloads to be resumed, and lets you rapidly clone the repo to a number of locations on disk without triggering a obtain once more.
Multiple completely different quantisation codecs are provided, and most users solely want to select and download a single file. If a user’s enter or a model’s output incorporates a sensitive phrase, the model forces users to restart the dialog. Highly Flexible & Scalable: Offered in mannequin sizes of 1.3B, 5.7B, 6.7B, and 33B, enabling customers to choose the setup most suitable for their requirements. The paper introduces DeepSeekMath 7B, a big language mannequin that has been pre-educated on a massive quantity of math-related data from Common Crawl, totaling a hundred and twenty billion tokens. First, they gathered a massive amount of math-related information from the net, together with 120B math-associated tokens from Common Crawl. Step 3: Instruction Fine-tuning on 2B tokens of instruction knowledge, resulting in instruction-tuned models (DeepSeek-Coder-Instruct). This knowledge, mixed with natural language and code knowledge, is used to continue the pre-training of the DeepSeek-Coder-Base-v1.5 7B model. Improved code understanding capabilities that permit the system to better comprehend and reason about code.
If you loved this article and you would like to get a lot more facts with regards to ديب سيك kindly pay a visit to our web site.
- 이전글The 10 Scariest Things About Double Glazed Window Repair Near Me 25.02.01
- 다음글Five Killer Quora Answers On Repairing Window 25.02.01
댓글목록
등록된 댓글이 없습니다.